> to Japanese Pages1. Summary
In this post, I explained “GlusterFS” as one of the source code synchronization solutions between web servers in a clustered environment. If we use this solution, the difference in source code due to deployment time lag will not occur between web servers. In addition, since “GlusterFS” is a distributed parallel fault tolerant file system, the effective range of this solution is not limited to Web servers. Depending on how you use it, you can build any fault tolerant file system on a large system.2. GlusgerFS Introduction
Are you using “rsync” or “lsyncd” for synchronzing the file system between each node in a business cluster environment? To make the story clearer, I will explain web servers as an example, but this issue is not limited to web servers. There are several ways to synchronize project source code between web servers in a cluster environment. First, let's give some Bad know-how. For example, I often hear how to synchronize to each node using a shell script with “rsync” implemented. Even if you manually deploy to each node, the problem will be few if the system is small. However, even if synchronization is automated using “cron” with the shortest period, source code differences will occur for up to one minute. In addition, I sometimes hear how to automatically detect source code changes using “lsyncd” and synchronize incrementally to each node. However, this synchronization method may take several tens of seconds at the shortest before synchronization is completed. Furthermore, these synchronization methods are unidirectional synchronization, so there are no guarantee of data consistency. I also hear pretty much how to automatically deploy to each node using ci tools. However, these synchronization methods only fill the time difference between manual and automatic, which is not a fundamental solution. If these synchronization processes are performed to each node by serial processing, there will be a time difference of “number of nodes x time difference” until synchronization is completed. It would be better to do it at least by parallel processing. If these statuses are not a problem in UX, data management and other aspects, this post will be useless. If there is a problem, there are a number of these solutions. As one of its solutions, you have a way to use “GlusterFS.” GlusterFS is a distributed parallel fault tolerant file system. One of the advantages of using GlusterFS is that fault-tolerant design can be realized, such as file system distribution, synchronization, capacity increase/decrease can be realized with no system stop. Naturally, synchronization is bidirectional and there is no concept of master and slave. However, you should not include files in this volume what will continue to be locked by the daemon. If you do not make a mistake in usage, GlusterFS will do a great deal of power. In this post, I will explain how to implement GlusterFS. In this post, I will not announce actual measurements on sync speed, so you should implement and judge.3. GlusterFS Architecture
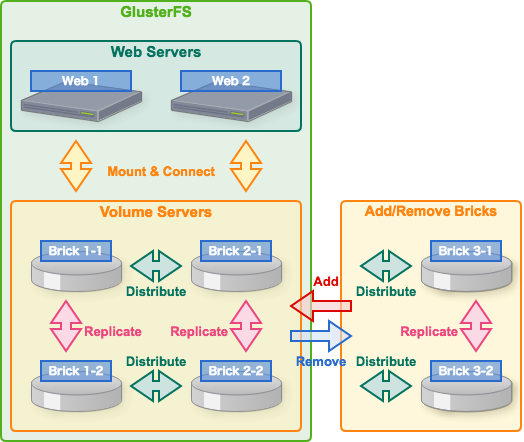
The following figure is a rough concept of GlusterFS.In addition, the following figure is a structure example of this post.It does not prepare volume server cluster, it is a simple self-contained structure. The Web server itself is a volume server and a client, and it is a mechanism that mounts from the client and connects to its own volume. Naturally, it is possible to change the system configuration by increasing/decreasing the brick.4. GlusterFS Environment
CentOS-7 GlusterFS 3.125. GlusterFS Servers Configuration
5-1. Install GlusterFS servers
# Both Web Server 1 and 2$ sudo yum -y install centos-release-gluster $ sudo yum -y install glusterfs-server5-2. Startup GlusterFS servers
# Both Web Server 1 and 2$ sudo systemctl start glusterd $ sudo systemctl enable glusterd $ sudo systemctl status glusterd5-3. Set GlusgerFS hosts name
# Both Web Server 1 and 2$ sudo vim /etc/hosts10.0.0.1 web1.example.com 10.0.0.2 web2.example.com5-4. Create GlusgerFS storage pool
# Only Web Server 1$ sudo gluster peer probe web2.example.com5-5. Confirm GlusgerFS storage pool
# Both Web Server 1 and 2$ gluster peer status5-6. Create GlusterFS volume
# Only Web Server 1$ sudo gluster volume create server replica 2 web1.example.com:/server/ web2.example.com:/server/ force5-7. Confirm GlusgerFS volume information
# Both Web Server 1 and 2$ sudo gluster volume info5-8. Start GlusgerFS volume
# Only Web Server 1$ sudo gluster volume start server5-9. Conform GlusgerFS volume status
# Both Web Server 1 and 2$ sudo gluster volume status6. GlusterFS Clients Configuration
6-1. Install GlusgerFS Clients
# Both Web Server 1 and 2$ sudo yum -y install glusterfs glusterfs-fuse glusterfs-rdma6-2. Mount Client to Server
# Web Server 1$ sudo mkdir /client $ sudo mount -t glusterfs web1.example.com:/server /client $ sudo df -Th# Web Server 2$ sudo mkdir /client $ sudo mount -t glusterfs web2.example.com:/server /client $ sudo df -Th6-3. Auto mount GlusgerFS Server
# Web Server 1$ sudo vim /etc/fstab# Web Server 2web1.example.com:/server /client glusterfs defaults,_netdev 0 0$ sudo vim /etc/fstaboweb2.example.com:/server /client glusterfs defaults,_netdev 0 06-4. Test GlusgerFS replication
# Web Server 1$ sudo cd /client $ sudo touch test.txt $ sudo ls# Web Server 2$ sudo cd /client $ sudo ls $ sudo rm text.txt# Web Server 1$ sudo ls7. GlusgerFS Conclusion
In this post, I explained “GlusterFS” as one of the source code synchronization solutions between web servers in a clustered environment. If you use this solution, the difference in source code due to deployment time lag will not occur between web servers. In this way, once we have the foundation of the system, we will not have to use the CI tools desperately. In addition, since GlusterFS is a distributed parallel fault tolerant file system, the effective range of this solution is not limited to Web servers. Depending on how you use it, you can build any fault tolerant file system on a large system.
2017-12-17
Distributed Parallel Fault Tolerant File System with GlusterFS


 AiR&D Inc. CTO & Full Stack Engineer
AiR&D Inc. CTO & Full Stack EngineerWARP-WG Founder: https://warp-wg.org/
A member of IEEE, ACM, IEICE, Information Processing Society, IETF, ISOC, Artificial Central & Cranial Nerves, ScaleD.
@KyojiOsada
https://twitter.com/KyojiOsada/
@kyoji.osada
https://www.facebook.com/kyoji.osada/
# GitHub
https://github.com/KyojiOsada/
# Tech Blog for Japanese
https://qiita.com/KyojiOsada/
# Blog for Japanese
https://kyojiosada.hatenablog.com/
https://www.linkedin.com/in/kyojiosada/
Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment